Table of Contents
- Feeling nostalgic
- Tracing the rays with parry3d
- Cutting the corners
- Getting to know portable-simd
- Circling back
- Going wide with rayon
- Fancying up with checkers
- Finishing up
- Getting closure
You can see the final code at https://github.com/batonius/ray-ten and play the wasm build at https://batonius.github.io/ray-ten/.
Feeling nostalgic
If you watched Black Mirror: Bandersnatch then you know that the UK in the 80s was booming with small-scale game development. For a variety of reasons, the dominant gaming platforms till the end of the decade were not consoles like NES, but locally made home computers. That meant that if you were a gamer you already had all the hardware you needed to make a game yourself, provided you have enough patience to read a book or two. With no license fees and no cartridges to produce, the cost of making and publishing video games was small enough for one/two-men teams to fill the market with games of varying quality. The dominant platform was the legendary ZX Spectrum.
A decade later, in the 90s, this once vibrant scene found a second life far in the East, where the post-Soviet generation made their first steps at personal computing. A ZX Spectrum clone was the home computer of choice because of its relatively low cost and vast software library, all of it pirated. Sure, playing on a Russian Spectrum clone wasn't as fun as playing on a Chinese NES clone - it lacked sprites, a sound chip (unless you were a lucky one with the 128K+ model), gamepads had only one button, and you had to wait for 5+ minutes for a game to load from a tape recorder (again, unless you were fortunate enough to have a floppy controller). But once you learned how things worked, every game however bland was not only an entertainment but also a puzzle and an inspiration, something you could deconstruct and reconstruct if only you tried hard enough.

One such game was room ten, written in 1986 by two Brits. It can be described as a first-person 3D pong, and despite having as boring and formulaic synopsis for the period as possible, the game itself was well written, had a nice visual style and played flawlessly, albeit slowly.
Here we have more than enough to impress a young mind: wired 3D graphics, textured floor, realistic inertia, there's even a ball's shadow. No wonder that years later, when I found myself with too much free time on my hands, this was the game my not-so-young-yet-still-impressed mind reminded me of.
Of course writing a 3D game in 2022 doesn't have the same vibe as writing a 3D game for ZX Spectrum - instead of using up CPU cycles putting bytes directly into video memory, we use GPUs, graphics APIs and game engines. Rendering inside of a box with a ball in it should be trivial - and it is (unless you skip the engine part). The result is very fast - way too fast to be interesting. I needed a twist.
Tracing the rays with parry3d
So I decided to skip the entire graphics pipeline and use hand-woven ray tracing. True, it had nothing to do with staying true to the source: the original game didn't use it, the authors were practical. I, apparently, was not.
By that time I had some experience with ray tracing - I implemented a renderer in C++ a decade or so ago for a Coursera course. All I remembered was that ray tracing is easy to implement and very slow to render. I remembered right.
Ray tracing must be the most straightforward rendering approach, being the reverse of how vision works in real life: instead of catching rays of light with retina we project them, follow them as they bounce around the scene, collecting color information on the way.
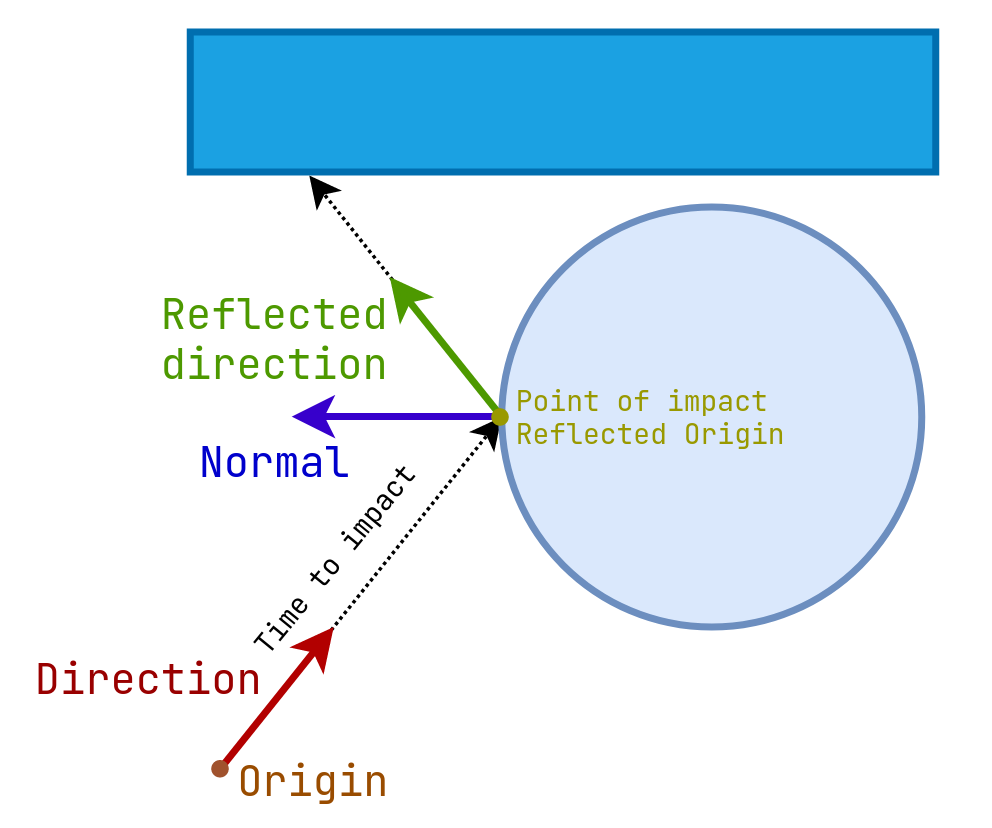
From the math point of view, rays are just a pair of two 3D vectors, one pointing to the origin of the ray, and the other being its direction.
To follow the ray as it reflects around the scene we first have to find the closest object the ray hits ("intersects") - the object with the smallest time of impact (toi).
That requires iterating over all the objects, calculating intersection points in different ways depending on the object's shape.
This is the most computationally expensive part of the rendering, the renderer spends most of its time doing basic math solving a lot of linear and quadratic equations.
Once we find the closest object, we compute the object's surface normal at the point of impact (poi) and create a new ray with its origin at the point of impact and direction reflected using the normal.
Each reflection adds to the final color of a pixel depending on the properties of the material at the point of impact.
The cycle continues until either the surface we hit isn't reflective or the reflection depth limit has been reached.
Despite wanting to reinvent the wheel for no reason at all, I wasn't ready to reinvent the wheel yet, so after refreshing my memory with a tutorial I set off looking for a library to do all the heavy lifting for me. Soon enough I found parry, part of the impressive Dimforge family of numerical libraries. The 3D version of the library, parry3d, implements a wide array of shapes and provides a method to intersect each of them with a ray, producing surface normals. That's, like, 2/3 of a ray tracer in a couple of imports, all I had to add was the material system to deal with reflection and color. The core of the renderer looked like this:
(all the parry3d types are explicitly qualified to show the extent I rely on the library)
pub struct Body {
shape: Box<dyn parry3d::shape::Shape>,
translation: parry3d::math::Isometry<parry3d::math::Real>,
material: Box<dyn Material>,
}
pub struct Scene {
bodies: Vec<Body>,
}
impl Scene {
pub fn ray_color(&self, ray: parry3d::query::Ray, depth: u32) -> Color {
if depth == 0 {
// recursion's base case
return Color::new(0.0, 0.0, 0.0);
}
if let Some((body_idx, intersection)) = self.find_closest_body(ray) {
match self.bodies[body_idx].material.interact_with_ray(
&ray,
ray.point_at(intersection.toi),
intersection.normal,
) {
// no reflection - no recursion
RayInteractionResult::Colored(color) => color,
RayInteractionResult::Reflected { ray, coef, offset } => {
// recursion
offset + coef * self.ray_color(ray, depth - 1)
}
}
} else {
self.ambient_color(ray)
}
}
fn find_closest_body(&self, ray: parry3d::query::Ray) ->
Option<(usize, parry3d::query::RayIntersection)> {
let mut min_toi = std::f32::MAX;
let mut closest_body = None;
for (body_idx, body) in self.bodies.iter().enumerate() {
if let Some(intersection) =
// all the math happens here, thanks parry3d!
body.shape.cast_ray_and_get_normal(
&body.translation,
&ray,
min_toi,
true,
) {
min_toi = intersection.toi;
closest_body = Some((body_idx, intersection));
}
}
closest_body
}
}
Putting it all together, I got this beauty:

It took 1.8s to render a box with a ball in it, so if I were to go full multicore at this point I would have needed a 110-core CPU for my game to produce the respectable 60fps. Something had to be done.
Cutting the corners
First let's point out some obvious performance pitfalls in the code above:
dyn Traits. That's an easy one: virtual methods confuse pipelining, branch predictor and prevent inlining. Calling them several times for each pixel adds up very quickly.- Recursion.
Scene::ray_coloris recursive but not tail recursive, so the compiler is unlikely to replace it with a loop, leaving us with a full-blown function call, stack frame allocating, argument passing, result returning and all that. - Generality.
parry3dis an excellent library with a lot of functionality, but that requires more general code than we actually need. And generality comes at cost. - A lot of RNG. Not shown above, but the material calculations required a lot of randomness, and RNG is slow.
Now lets look again at the original game we're trying to clone:
- The only two types of shapes we need are an axis-aligned infinite plane and a sphere. No, we don't need boxes to draw paddles, we can emulate them with spherical caps.
- Perfect metallic reflection is good enough for all surfaces just because.
- The number of objects is known in advance. The positions of planes and their normals are fixed.
- Tracing happens inside the box, meaning a ray has to hit something eventually.
With all this in mind I started off again.
Every object got an entry in the Obstacle enum, with all the properties stored in several const arrays.
Intersecting an axis-aligned plane was reduced to a one-dimensional equation, and intersection of all the planes became a cascade of ifs, one for each dimension.
// Intersecting planes along the X axis
if ray.dir[0].abs() > EPSILON {
if ray.dir[0] > 0.0 {
let toi = (OBSTACLE_OFFSETS[Obstacle::Right as usize] - ray.origin[0])
/ ray.dir[0];
if toi < min_toi {
min_toi = toi;
closest_obstacle = Some(Obstacle::Right);
}
} else {
let toi = (OBSTACLE_OFFSETS[Obstacle::Left as usize] - ray.origin[0])
/ ray.dir[0];
if toi < min_toi {
min_toi = toi;
closest_obstacle = Some(Obstacle::Left);
}
}
}
Unfortunately spheres are already perfect, so I still had to eat up the cost of solving a quadratic equation. On each step we updated the closest obstacle so far, and in the end we used it to produce the normal and the colors.
if let Some(obstacle) = closest_obstacle {
let poi = ray.point_at(min_toi);
let normal;
if obstacle == Obstacle::Sphere {
normal = self.sphere_normal(&poi);
} else {
normal = OBSTACLE_NORMALS[obstacle as usize];
}
let reflection_dir = ray.dir - 2.0 * ray.dir.dot(&normal) * normal;
ray = Ray {
origin: poi,
dir: reflection_dir,
};
offset_color += coef_color * OBSTACLE_COLORS[obstacle as usize];
coef_color *= Color::new(0.5, 0.5, 0.5);
}
The recursion was replaced with straight-up iteration with offset_color and coef_color used to store intermediate color state.
The result was beautiful.

Taking only 300ms to produce, the speed-up was an impressive 6x, but 3fps still isn't enough. So what's next?
Ray tracing is what they call an embarrassingly parallel problem - each ray bounces around independently making no changes to the global state, returning a scalar value, making it possible to compute each of them in parallel with no coordination costs. Keeping in mind that the free lunch has been over for 17 years, by now we all know the drill - it's time to go wide core-wise, right? Wrong, there's still a way to exploit the embarrassing parallelism on a single core.
Getting to know portable-simd
Most modern CPUs have a way to operate on several values simultaneously, provided they are packed in vector registers. With special instructions you can tell the CPU to treat such a vector register, say 256 bits wide, as eight 32-bit floats, and to add them to another eight floats stored in another vector register. That's 8 operations at the cost of one (not really, but close enough). The approach is called SIMD, after Single Instruction, Multiple Data.
SIMD extensions have been a thing for 25+ years now, most ISA have them, wasm including.
The most recent on x86-64 being avx and avx-512, providing 256- and 512-bit wide vector registers respectively.
You can safely bet on a modern PC to support at least the former, providing you with a way to manipulate these 256 bits as 32 bytes, 8 floats or 4 doubles simultaneously.
These individual scalar values inside a vector register are called "lanes".
As a regular programmer you don't usually interact with SIMD directly, and for good reasons:
- Most tasks are linear and have nothing to gain from SIMD.
- Many of those which do can be auto-vectorized by a modern compiler with no special effort required.
- SIMD code is arch-specific and ISA-version specific, so not only you have to use compiler intrinsics with names like
_mm512_mask_4dpwssds_epi32, your code is now full ofunsafeand tied to a specific version of SIMD for a specific architecture.avx-512code won't work on olderx86-64CPUs and can't be easily ported toaarch64or evenavx-1024once it's out.
Now, the first two points don't apply to our task at hand - ray tracing has a lot to gain from SIMD, and the compiler isn't able to auto-vectorize the code.
The last issue can be solved the same way any problem in Software Engineering can be solved - by adding yet another abstraction layer, in this case that would be portable-simd.
portable-simd is an effort to bring ergonomic SIMD to the Rust standard library.
Currently, it's unstable and requires the nightly toolchain.
You can actually write SIMD code in stable Rust by using intrinsics from std::arch, but it has all the downsides described above.
Using the library is very straightforward: all the magic happens in the Simd struct, which implements traits from std::ops such as Add and Mul, in addition to SIMD-specific methods like reduce_sum.
This way you can define, say, type Reals = Simd<f32, 8>, a vector type consisting of 8 lanes of f32 floats, and then use the values of this type as if they were scalar (thanks, operator overloading!):
fn foo(a: Reals, b: Reals) -> Reals {
(a + b * b).sqrt()
}
With -C target-cpu=native -C opt-level=3 this results in
example::foo:
mov rax, rdi
vmovaps ymm0, ymmword ptr [rdx] ; Load the second argument to ymm0
vmulps ymm0, ymm0, ymm0 ; Multiply each lane by itself
vaddps ymm0, ymm0, ymmword ptr [rsi] ; Add the first argument to it lane-wise
vsqrtps ymm0, ymm0 ; Compute square roots for each lane
vmovaps ymmword ptr [rdi], ymm0 ; Save the results
vzeroupper
ret
If you don't know assembly here's the key - instructions with the ps suffix treat their arguments - 256-bit ymm registers in this case - as parallel (i.e. vectors of) single-percision values (i.e. 32-bit floats).
In other words, in the code above each v*ps instruction makes 8 operations simultaneously.
The library makes the best effort to match the specific Simd type to the underlying SIMD architecture.
In case of wasm with the simd128 extension or x86 with the SSE2 extension the code above will use two 128-bit registers.
If the target platform has no SIMD at all, the library will emulate it with scalar operations, so the code above can be compiled with -C target-cpu=pentium, a CPU with no SIMD capabilities, the result being four dozens x87 instructions - not fast, but good enough to do the math.
Programming isn't just pure math, tho - there's also branching, a way to change control flow based on some condition.
It works for scalar values, but with SIMD you have multiple values sharing the same control flow, you can't change it only for some of them.
Say you need to double all the lanes which are below 100.0.
Sure enough, Simd implements Index and IndexMut, so you can brute force it with
fn bar(mut a: Reals) -> Reals {
// Don't do this
for i in 0..8 {
if a[i] < 100.0 {
a[i] *= 2.0;
}
}
a
}
With -C target-cpu=native -C opt-level=3 this compiles to
example::bar:
mov rax, rdi
vmovss xmm1, dword ptr [rsi]
vmovss xmm0, dword ptr [rip + .LCPI1_0]
vucomiss xmm0, xmm1
ja .LBB1_16
vmovss xmm1, dword ptr [rsi + 4]
vucomiss xmm0, xmm1
ja .LBB1_2
.LBB1_3:
vmovss xmm1, dword ptr [rsi + 8]
vucomiss xmm0, xmm1
ja .LBB1_4
.LBB1_5:
vmovss xmm1, dword ptr [rsi + 12]
vucomiss xmm0, xmm1
ja .LBB1_6
; This goes on for 70+ lines
Thanks to loop unrolling by the compiler, we have 15 comparisons (vucomiss) and 15 branching (the j*) instructions, each ready to mess with the branch predictor.
You can see by the ss suffix that the instructions treat each vector register as a scalar single-percision value, meaning we've lost all the benefits of SIMD.
The solution to make branching in SIMD code efficient is very simple - just have no branches, write code linearly, with no ifs.
Instead, use the other magic type from portable-simd - Mask struct.
Mask treats a vector register as a number of bools, one corresponding to each lane in the Simd type.
When you compare the values of the latter lane-wise you get an instance of the Mask type, which you can then use to conditionally move values around, skipping these with false in their lane:
fn bar(a: Reals) -> Reals {
let mask = a.simd_lt(Reals::splat(100.0)); // "lt" = less than
let doubled_a = a * Reals::splat(2.0);
mask.select(doubled_a, a)
}
In the code above we first produce mask, comparing each lane with 100.0, and then select lanes from either a or doubled_a based on the lanes in Mask.
This way no branching in the control flow occurs - we double all the lanes, even those above 100.0, we just don't use the results we don't need.
In a way, it's a waste of computing resources, but assuming all the doubling happens in parallel, we don't waste any execution time.
Comparing to the first attempt the assembly is tiny and efficient:
example::bar:
vmovaps ymm0, ymmword ptr [rsi] ; Load the argument to ymm0
mov rax, rdi
; Compare values in ymm0 to a constant in memory, save to the mask
vcmpltps k1, ymm0, dword ptr [rip + .LCPI2_0]{1to8}
; Save the sum only to the lanes matching the mask
vaddps ymm0 {k1}, ymm0, ymm0
; Save the result
vmovaps ymmword ptr [rdi], ymm0
vzeroupper
ret
Even in edge cases, say when all the lanes are above 100.0, there's sometime no point in explicit branching (which we can do with if mask.any()) - it messes up the instruction pipelining, and the overall performance may be worse.
So that's the way you use SIMD - compute all the values and then keep only the ones you need.
Circling back
With all this knowledge I went back to redesigning ray-ten around portable-simd.
The renderer being already extremely dumbed-down, methods provided by the Simd type were just enough.
First, the basic types
pub const LANES: usize = 8usize;
pub type Real = f32;
pub type Reals = Simd<Real, LANES>;
pub type Mask = SimdMask<i32, LANES>;
pub struct Points {
pub xs: Reals,
pub ys: Reals,
pub zs: Reals,
}
pub type Colors = Points;
pub type Vectors = Points;
pub struct Rays {
pub origins: Points,
pub dirs: Vectors,
}
//Lots of Add/Mul/Div implementations
As a side note, these are large types, Rays being 2 * 3 * 8 * 4 = 192 bytes.
My first instinct was to pass them around via references, which made doing math with them very awkward.
So I switched to passing them around by value and to my surprise the performance stayed the same - apparently most operations were inlined anyway, so no actual passing was taking place.
And when it did, the compiler was smart enough to use 6 vector registers to pass Rays values around.
Now I was tracing LANES rays at the same time.
After I encapsulated all the math and the state in a separate type, the tracing function finally started to look sane:
pub fn trace_rays(scene: &Scene, rays: Rays, max_depth: usize) -> Colors {
let mut projections = RaysProjections::new(scene, rays, max_depth);
loop {
projections.intersect_with_sphere(Sphere::Ball);
projections.intersect_with_sphere(Sphere::NearPaddle);
projections.intersect_with_sphere(Sphere::FarPaddle);
projections.intersect_with_aa_plane(Plane::Top);
projections.intersect_with_aa_plane(Plane::Bottom);
projections.intersect_with_aa_plane(Plane::Left);
projections.intersect_with_aa_plane(Plane::Right);
projections.intersect_with_aa_plane(Plane::Near);
projections.intersect_with_aa_plane(Plane::Far);
if projections.reflect() {
break;
}
}
projections.finish(Colors::splat(1.0, 1.0, 1.0))
}
Using two loops here had a measurable impact on the performance, apparently manual loop unrolling still sometimes wins.
RaysProjections holds a number of Simds, one for each object attribute I need.
Each intersect_with_* method call updates lanes in these attributes if an intersection in that lane was closer than the previous closest.
Here's the easy one:
fn intersect_with_aa_plane(&mut self, plane: Plane) {
// Get plane's attributes from scene
let offset_within_axis = Reals::splat(self.scene.plane_offset(plane));
let normal = Vectors::from_single(self.scene.plane_normal(plane));
let color = Colors::from_single(self.scene.obstacle_color(Obstacle::Plane(plane)));
// Get the axis the plane is on
let axis = self.scene.plane_alignment_axis(plane);
let toi =
(offset_within_axis - self.rays.origins.get_axis(axis))
/ self.rays.dirs.get_axis(axis);
let mask = toi.simd_gt(Reals::splat(MIN_TOI)) & toi.simd_lt(self.min_toi);
update_reals_if(&mut self.min_toi, mask, toi);
self.obstacle_colors.update_if(mask, color);
self.obstacle_normals.update_if(mask, normal);
}

Going wide with rayon
There's nothing much to say here, rayon just works 🤷.
I added rayon = "1.5" to my Cargo.toml, put use rayon::prelude::*; in the top and replaced chunks_exact_mut(LANES) with par_chunks_exact_mut(LANES).
I got 7.6x speed-up on my 8-core machine, that got me down to 10ms per frame, which is more than enough for a game.
Quite anti-climatic, but oh well.
Fancying up with checkers
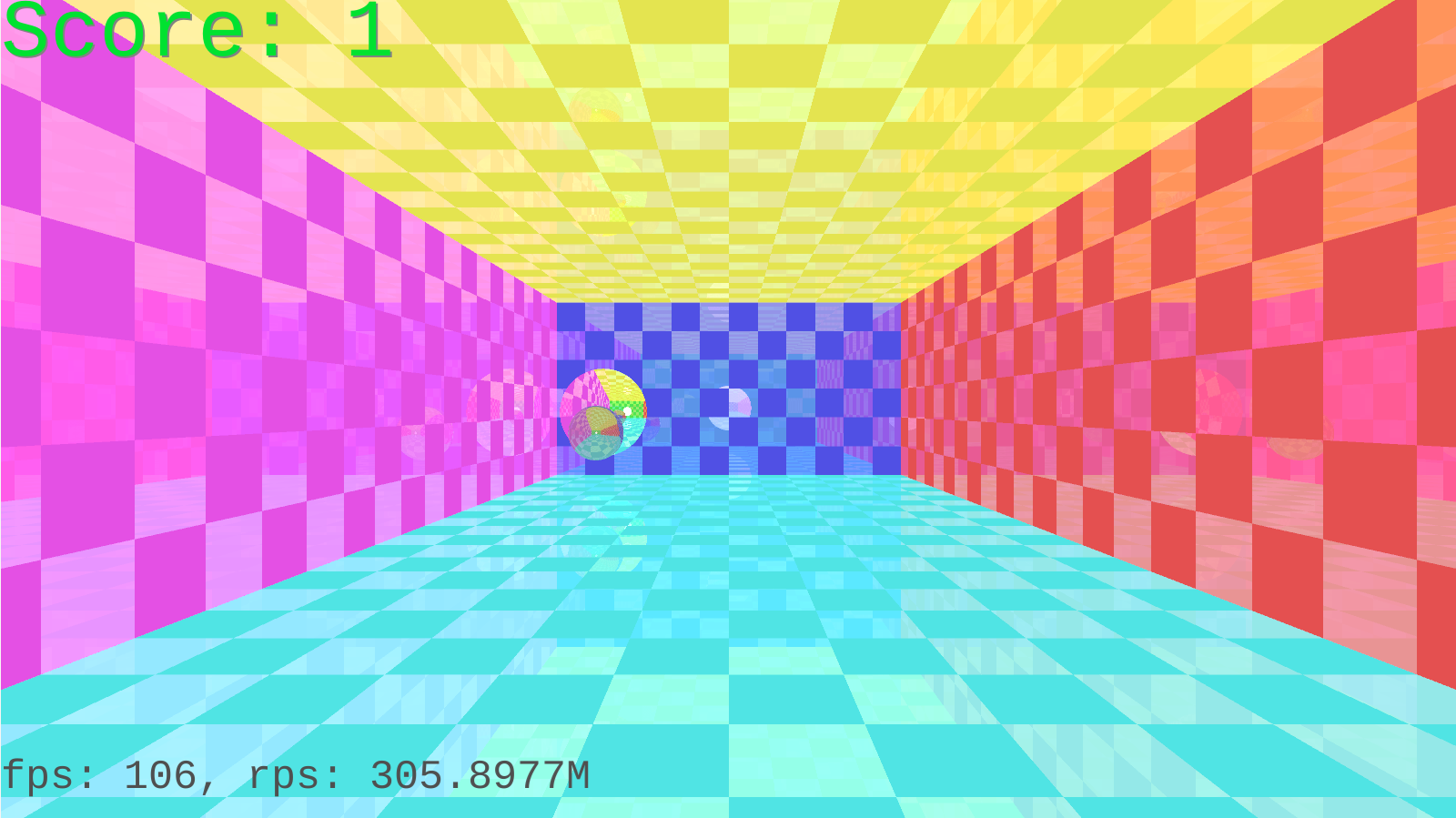
To spice things up a little I added the checker pattern to all planes. The math is quite simple - convert surface coordinates to integers, add them up and see if the sum is odd. The problem is that using surface coordinates slows things up a lot. So instead of using 2d surface coordinates at the point of impact I used 3d coordinates, as if the space itself was made of cubes laid in the checker pattern. Now all I had to do was to check whether the point of impact was within such a cube or not.
let mut offset_pois = self.rays.origins + self.rays.dirs * toi;
offset_pois *= 1.5;
let checkered_mask = mask
& ((offset_pois.xs.cast::<Integer>()
+ offset_pois.ys.cast::<Integer>()
+ offset_pois.zs.cast::<Integer>())
% Integers::splat(2))
.simd_eq(Integers::splat(0));
update_reals_if(&mut self.obstacle_reflectances, checkered_mask, ZEROS);
Here's the final result
Finishing up
With rendering done, the interesting part was over. I used macroquad to show the image and the UI and to process inputs. I added a trivial collision detection, inertia, scoring system, and menus, all straightforward. None of these subsystems had any effect on the performance, so no time was spent optimizing them.
Porting to wasm was surprisingly easy, mainly thanks to macroquad, the only casualty was rayon - it's possible to use Web Workers for the thread pool, but that's tricky and requires the HTTP server to set a COOP/COEP headers. GitHub Pages doesn't set these, and publishing this version would be problematic anyway. So I ended up disabling rayon on wasm. The resulting wasm performance was about half of that of a single-threaded native version, the results vary depending on a browser - Firefox being 2x times slower than Chrome.
Getting closure
When I started the project I wanted to busy myself for some time and maybe to relive that thrill of coming up with optimal solutions for useless problems all with limited resources. Now, modern PCs are hardly "limited", but that only means you have to set unreasonable tasks for yourself, aim for the stars, to get yourself interested. Getting the 180x speed-up was rewarding, although the hardest part was to finish the project once I got decent fps and do the boring stuff like UI. I'm glad I did tho.